
このブログでは、外部から侵入した脅威や内部犯行の検知について、検知の基本的な考え方を侵害の状況毎に説明するとともに、機械学習を活用した検知の有効性について解説します。これらの脅威は様々な工夫を凝らして検知をかいくぐろうとしますが、防御側の優位性を存分に活用することで検知の可能性を高めることができます。また、検知のための運用負担が大きいと結局断念することになりかねませんので、運用負担の軽減の視点でも機械学習の活用の有効性を紹介します。
目次
1. 組織内で発生する脅威の検知
組織内に侵入した脅威や内部犯行の検知を考える時、攻撃側に比較して防御側が有利な点は、攻撃側より多くの情報を防御に活用できる点です。様々な対象(ユーザ、エンドポイント、ネットワークなど)の、比較的長い期間的のログ情報を入手できるので、これらの情報を検知に活用しない手はありません。
もちろん、対象が多くなれば大量のデータを処理する事になり、コンピューティングパワーを含め対策基盤としては強力なものが要求されます。ただ、適切な自動化を行う事で運用者の負担を大きく軽減できます。
2. 検知する脅威の状況と着目ポイント
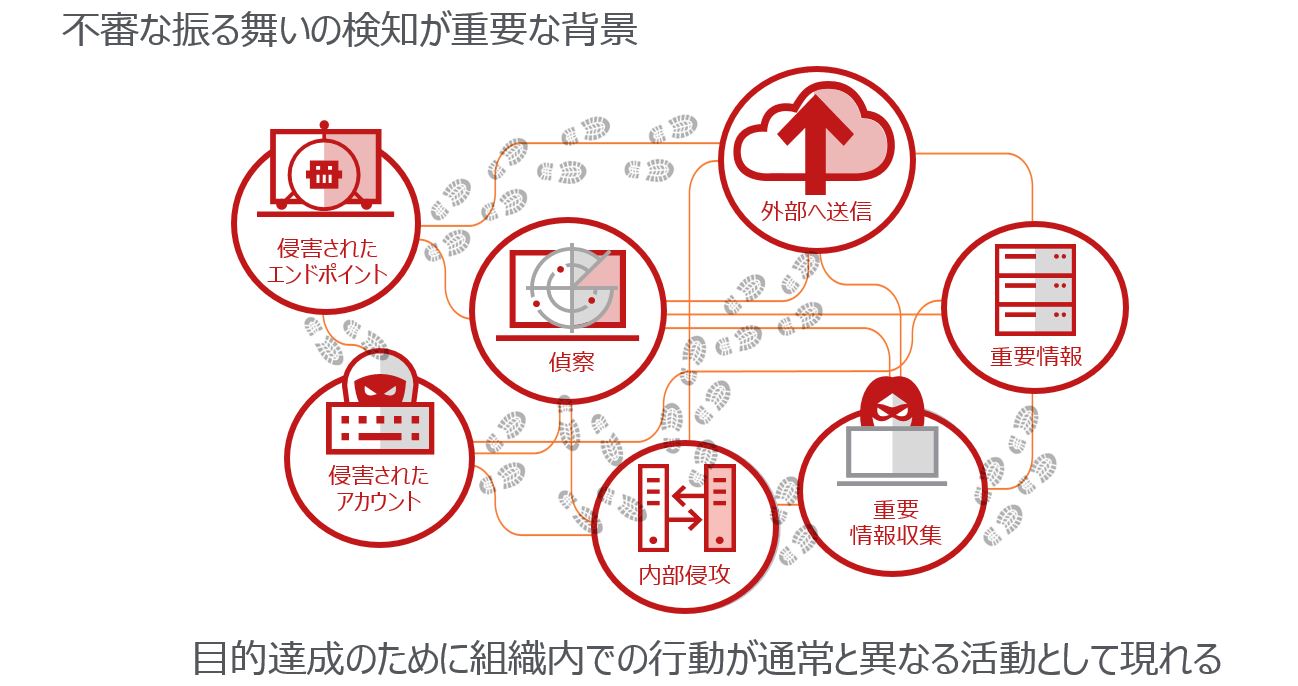
今回は、以下を対象にしてそれぞれについて検知の際の着目点を説明します。
・侵害されたアカウント
・侵害されたエンドポイント
・偵察(内部スキャン)と内部侵攻
・情報収集と外部へ送信
2-1 侵害されたアカウントの検知
侵害されたアカウントの検知のポイントは、通常このアカウントで行われるアクティビティと異なる行動が現れる可能性が高いことです。解りやすい例では、通常使用されている時間とは異なる時間、通常と異なる国からログイン、短期間に異なる地域からログインが発生するなどがあります。他にも、通常と異なるサーバーにアクセスしたり、異なるアプリケーションサービスを使用することも検知のきっかけになります。
2-2 侵害されたエンドポイントの検知
場合によってはアカウントとエンドポイントの侵害は同じように感じるかもしれませんが、着目点が少々異なります。エンドポイントが侵害されるとバックドアがしかけられる可能性が高いため、外部への通信などの視点が重要になります。また、通常見られないアプリケーションやプロセスの活動、そしてレジストリの設定も検知に活用できます。
2-3 偵察(内部スキャン)と内部侵攻の検知
特定の個人のPC内の重要情報を狙う場合もありますが、組織内のネットワーク構成を調査して重要データのありそうなサーバーを探索し盗み出そうとする場合もあります。このようなケースでは調査のためにスキャン用のアプリケーションが実行されたり、調査のためにOSのコマンドが実行されたり、アカウントの試行が発生することがあるので検知のきっかけに活用できます。
2-4 情報収集と外部へ送信の検知
犯行実行時に別システムから侵入して重要な情報を入手しようとする場合、PSExecやリモートデスクトップツールなどを使用してデータの収集活動を行う場合があります。また、情報を収集されるシステム側では、データに対するアクセスの発生時間、アクセス方法、データ量が通常と異なり検知のきっかけとして活用できます。
2-5 着目点は活動/振る舞いの変化や違い
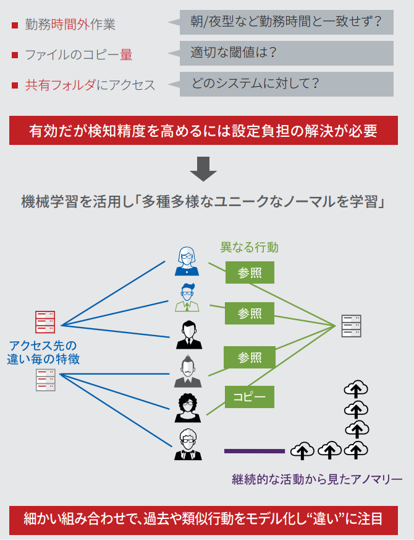
各侵害のケースごとに着目点の例を紹介しましたが、これらの該当エンドポイントやユーザの行動や振る舞いが「過去と比較して異なる」とか、「同じような行動傾向のグループの行動傾向と比較して異なる」(例:同じサーバーやサービスを使用するユーザ等)というアプローチをとります。そのために、エンドポイントやユーザの長期のデータから行動を把握し、細かくグループ化して状況を把握しつつ、変化や違いを基にリスクが高いと考えられる行動を検知するようにします。
3. 検知と運用負担
検知しようとする活動が明確な場合は特定の検知ルールを、各セキュリティシステムやSIEM等で定義するのが手っ取り早いです(例えば、短時間に人間が実行できないほど大量のログイン失敗が同一アカウントで発生など)。しかし、様々な状況(ユーザの行動特性が異なったり、サーバーで提供されるサービスが異なったり)の検知のために数多くのルールを書かなければならない場合、大まかに書くと誤検知(過検知や非検知)が多くなったり、細かくルールを書くとルールの作成や管理など運用負担が大きくなるのが注意点です。
ここで機械学習の出番です。様々なルールを記述する代わりに、行動を示すデータを継続的に学習させることで検出する方法があります。機械学習であれば、個別のエンドポイント毎、ユーザ毎に学習させ、そこで得られる情報からグループ化することもできるので、部署等を定義したり人事異動やネットワーク構成変更毎に手作業で修正することなく、継続的な学習の中で調整されます。また、運用者からすると面倒になりがちな様々な視点でグループ化させることも、自動的に行われるので機械学習を活用した仕組みの優位性です。
機械学習も事前(開発時)にモデリングをしっかりされていることが前提になりますが、(処理データ量をこなすためのサイジングは別として)ルールをほぼ書かずにリスクが高いと考えられる行動を検出できるようにできます。特に教師無し機械学習を中心とした仕組みを使うと運用を開始してからのチューニングもほぼ必要なしに検知させることができます。
4. 検知のために使用する学習データ例
最後にリスクの高い活動を検知するのに役立つログデータの例と検知例を紹介します。
| 検知対象 | 活用できるログデータ例 |
| 侵害されたアカウント | 認証システム、ディレクトリサービス、OS、フォルダ/ファイル共有、VPN、重要データを保存しているリポジトリ |
| 侵害されたエンドポイント | Webプロキシのログ、ディレクトリサービス |
| 内部スキャンと侵攻 | 認証システム、重要データを保存しているリポジトリ、フォルダ/ファイル共有、OS |
| 情報収集と外部への送信 | ディレクトリサービス、重要データを保存しているリポジトリ、プリンタ、Webプロキシ |
以下は、教師無し機械学習の仕組みでリスクの高い行動を検出するMcAfee Behavioral Analyticsがあるユーザの行動のリスクが高いと判断した検出例です。教師無し機械学習の良さである事前のルール設定なしで、多様なログデータを対象に継続的に、かつ分類をしながら、過去に見られた行動との比較や、類似行動のユーザとの比較等を行ってリスクを分析しています。

5. まとめ
今回は外部から侵入した脅威や内部犯行の検知について、検知の際の着目点、検知における機械学習の有効性、活用できるログデータの例を紹介しました。セキュリティ運用は検知精度の向上や運用負担軽減が課題になります。脅威や攻撃手法に関する情報を大量に入手して検知に活用するのも大切なアプローチですが、今回は自組織の日々の活動に関する情報を有効活用して脅威を検知する仕組みを取り上げました。機械学習のようなテクノロジーを有効活用して大量データを処理しリスクの高い行動を早期に検知する仕組みは、普段の運用負担を自動化で軽減できたり、これまでより早い段階で対応作業が行えることでセキュリティ運用の負担軽減に貢献します。
著者:マカフィー株式会社 マーケティング本部
